
Forthcoming
Abstract
Generative artificial intelligence (AI) has shown incredible leaps in performance across data of a variety of modalities including texts, images, audio, and videos. This affords social scientists the ability to annotate variables of interest from unstructured media. While rapidly improving, these methods are far from perfect and, as we show, even ignoring the small amounts of error in high accuracy systems can lead to substantial bias and invalid confidence intervals in downstream analysis. We review how using design-based supervised learning (DSL) guarantees asymptotic unbiasedness and proper confidence interval coverage by making use of a small number of expert annotations. While originally developed for use with large language models in text, we present a series of applications in the context of image analysis, including an investigation of visual predictors of the perceived level of violence in protest images, an analysis of the images shared in the Black Lives Matter movement on Twitter, and a study of U.S. outlets reporting of immigrant caravans. These applications are representative of the type of analysis performed in the visual social science landscape today, and our analyses will exemplify how DSL helps us attain statistical guarantees while using automated methods to reduce human labor.
Abstract
Instrumental variables (IV) analysis is a powerful, but fragile, tool for drawing causal inferences from observational data. Sociologists increasingly turn to this strategy in settings where unmeasured confounding between the treatment and outcome is likely. This paper reviews the assumptions required for IV and the consequences of violating them, focusing on sociological applications. We highlight three methodological problems IV faces: (i) identification bias, an asymptotic bias from assumption violations; (ii) estimation bias, a finite-sample bias that persists even when assumptions hold; and (iii) type-M error, the exaggeration of effect size given statistical significance. In each case, we emphasize how weak instruments exacerbate these problems and make results sensitive to minor violations of assumptions. We survey IV papers from top sociology journals, finding that assumptions often go unstated and robust uncertainty measures are rarely used. We provide a practical checklist to show how IV, despite its fragility, can still be useful when handled with care.
Abstract
Analysts often seek to compare representations in high-dimensional space, e.g., embedding vectors of the same word across groups. We show that the distance measures calculated in such cases can exhibit considerable statistical bias, that stems from uncertainty in the estimation of the elements of those vectors. This problem applies to Euclidean distance, cosine similarity, and other similar measures. After illustrating the severity of this problem for text-as-data applications, we provide and validate a bias correction for the squared Euclidean distance. This same correction also substantially reduces bias in ordinary Euclidean distance and cosine similarity estimates, but corrections for these measures are not quite unbiased and are (non-intuitively) bimodal when distances are close to zero. The estimators require obtaining the variance of the latent positions. We (will) implement the estimator in free software, and we offer recommendations for related work.
2025
Abstract
Abstract
Abstract
Word embeddings are now a vital resource for social science research. However, obtaining high-quality training data for non-English languages can be difficult, and fitting embeddings therein may be computationally expensive. In addition, social scientists typically want to make statistical comparisons and do hypothesis tests on embeddings, yet this is nontrivial with current approaches. We provide three new data resources designed to ameliorate the union of these issues: (1) a new version of fastText model embeddings, (2) a multilanguage “a la carte” (ALC) embedding version of the fastText model, and (3) a multilanguage ALC embedding version of the well-known GloVe model. All three are fit to Wikipedia corpora. These materials are aimed at “low-resource” settings where the analysts lack access to large corpora in their language of interest or to the computational resources required to produce high-quality vector representations. We make these resources available for 40 languages, along with a code pipeline for another 117 languages available from Wikipedia corpora. We extensively validate the materials via reconstruction tests and other proofs-of-concept. We also conduct human crowdworker tests for our embeddings for Arabic, French, (traditional Mandarin) Chinese, Japanese, Korean, Russian, and Spanish. Finally, we offer some advice to practitioners using our resources.
2024
Abstract
We introduce a three-part framework for constructing persuasive messages, AutoPersuade. First, we curate a large collection of arguments and gather human evaluations of their persuasiveness. Next, we introduce a novel topic model to identify the features of these arguments that influence persuasion. Finally, we use the model to predict the persuasiveness of new arguments and to assess the causal effects of argument components, offering an explanation of the results. We demonstrate the effectiveness of AutoPersuade in an experimental study on arguments for veganism, validating our findings through human studies and out-of-sample predictions.
Abstract
The boardgame Diplomacy is a challenging setting for communicative and cooperative artificial intelligence. The most prominent communicative Diplomacy AI, Cicero, has excellent strategic abilities, exceeding human players. However, the best Diplomacy players master communication, not just tactics, which is why the game has received attention as an AI challenge. This work seeks to understand the degree to which Cicero succeeds at communication. First, we annotate in-game communication with abstract meaning representation to separate in-game tactics from general language. Second, we run two dozen games with humans and Cicero, totaling over 200 human-player hours of competition. While AI can consistently outplay human players, AI-Human communication is still limited because of AI s difficulty with deception and persuasion. This shows that Cicero relies on strategy and has not yet reached the full promise of communicative and cooperative AI.
Abstract
Machine learning (ML) methods are proliferating in scientific research. However, the adoption of these methods has been accompanied by failures of validity, reproducibility, and generalizability. These failures can hinder scientific progress, lead to false consensus around invalid claims, and undermine the credibility of ML-based science. ML methods are often applied and fail in similar ways across disciplines. Motivated by this observation, our goal is to provide clear recommendations for conducting and reporting ML-based science. Drawing from an extensive review of past literature, we present the REFORMS checklist (recommendations for machine-learning- based science). It consists of 32 questions and a paired set of guidelines. REFORMS was developed on the basis of a consensus of 19 researchers across computer science, data science, mathematics, social sciences, and biomedical sciences. REFORMS can serve as a resource for researchers when designing and implementing a study, for referees when reviewing papers, and for journals when enforcing standards for transparency and reproducibility.
2023
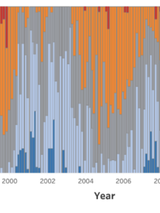
Abstract
Markets and policymakers around the world hang on the consequential monetary policy decisions made by the Federal Open Market Committee (FOMC). Publicly available textual documentation of their meetings provides insight into members’ attitudes about the economy. We use GPT-4 to quantify dissent among members on the topic of inflation. We find that transcripts and minutes reflect the diversity of member views about the macroeconomic outlook in a way that is lost or omitted from the public statements. In fact, diverging opinions that shed light upon the committee’s “true” attitudes are almost entirely omitted from the final statements. Hence, we argue that forecasting FOMC sentiment based solely on statements will not sufficiently reflect dissent among the hawks and doves.

Abstract
In computational social science (CSS), researchers analyze documents to explain social and political phenomena. In most scenarios, CSS researchers first obtain labels for documents and then explain labels using interpretable regression analyses in the second step. One increasingly common way to annotate documents cheaply at scale is through large language models (LLMs). However, like other scalable ways of producing annotations, such surrogate labels are often imperfect and biased. We present a new algorithm for using imperfect annotation surrogates for downstream statistical analyses while guaranteeing statistical properties -- like asymptotic unbiasedness and proper uncertainty quantification -- which are fundamental to CSS research. We show that direct use of surrogate labels in downstream statistical analyses leads to substantial bias and invalid confidence intervals, even with high surrogate accuracy of 80--90\%. To address this, we build on debiased machine learning to propose the design-based supervised learning (DSL) estimator. DSL employs a doubly-robust procedure to combine surrogate labels with a smaller number of high-quality, gold-standard labels. Our approach guarantees valid inference for downstream statistical analyses, even when surrogates are arbitrarily biased and without requiring stringent assumptions, by controlling the probability of sampling documents for gold-standard labeling. Both our theoretical analysis and experimental results show that DSL provides valid statistical inference while achieving root mean squared errors comparable to existing alternatives that focus only on prediction without inferential guarantees.
Abstract
Language models have recently broken into the public consciousness with the release of the wildly popular ChatGPT. Commentators have argued that language models could replace search engines, make college essays obsolete, or even write academic research papers. All of these tasks rely on accuracy of specialized information which can be difficult to assess for non-experts. Using 10 domain experts across science and culture, we provide an initial assessment of the coherence, conciseness, accuracy, and sourcing of two language models across 100 expert-written questions. While we find the results are consistently cohesive and concise, we find that they are mixed in their accuracy. These results raise questions of the role language models should play in general-purpose and expert knowledge seeking.

Abstract
Social scientists commonly seek to make statements about how word use varies over circumstances—including time, partisan identity, or some other document-level covariate. For example, researchers might wish to know how Republicans and Democrats diverge in their understanding of the term “immigration.” Building on the success of pretrained language models, we introduce the à la carte on text (conText) embedding regression model for this purpose. This fast and simple method produces valid vector representations of how words are used—and thus what words “mean”—in different contexts. We show that it outperforms slower, more complicated alternatives and works well even with very few documents. The model also allows for hypothesis testing and statements about statistical significance. We demonstrate that it can be used for a broad range of important tasks, including understanding US polarization, historical legislative development, and sentiment detection. We provide open-source software for fitting the model.

Abstract
We collect and analyze a corpus of more than 300,000 political emails sent during the 2020 US election cycle. These emails were sent by over 3000 political campaigns and organizations including federal and state level candidates as well as Political Action Committees. We find that in this corpus, manipulative tactics—techniques using some level of deception or clickbait—are the norm, not the exception. We measure six specific tactics senders use to nudge recipients to open emails. Three of these tactics—“dark patterns”—actively deceive recipients through the email user interface, for example, by formatting “from:” fields so that they create the false impression the message is a continuation of an ongoing conversation. The median active sender uses such tactics 5% of the time. The other three tactics, like sensationalistic clickbait—used by the median active sender 37% of the time—are not directly deceptive, but instead, exploit recipients’ curiosity gap and impose pressure to open emails. This can further expose recipients to deception in the email body, such as misleading claims of matching donations. Furthermore, by collecting emails from different locations in the US, we show that senders refine these tactics through A/B testing. Finally, we document disclosures of email addresses between senders in violation of privacy policies and recipients’ expectations. Cumulatively, these tactics undermine voters’ autonomy and welfare, exacting a particularly acute cost for those with low digital literacy. We offer the complete corpus of emails at https://electionemails2020.org for journalists and academics, which we hope will support future work.

Abstract
The empirical practice of using factor models to adjust for shared, unobserved confounders, Z, in observational settings with multiple treatments, A, is widespread in fields including genetics, networks, medicine, and politics. Wang and Blei (2019, WB) formalizes these procedures and develops the "deconfounder," a causal inference method using factor models of A to estimate "substitute confounders," Ẑ , then estimating treatment effects by regressing the outcome, Y, on part of A while adjusting for Ẑ . WB claim the deconfounder is unbiased when there are no single-cause confounders and Ẑ is "pinpointed." We clarify pinpointing requires each confounder to affect infinitely many treatments. We prove under these assumptions, a naïve semiparametric regression of Y on A is asymptotically unbiased. Deconfounder variants nesting this regression are therefore also asymptotically unbiased, but variants using Ẑ and subsets of causes require further untestable assumptions. We replicate every deconfounder analysis with available data and find it fails to consistently outperform naïve regression. In practice, the deconfounder produces implausible estimates in WB's case study to movie earnings: estimates suggest comic author Stan Lee's cameo appearances causally contributed $15.5 billion, most of Marvel movie revenue. We conclude neither approach is a viable substitute for careful research design in real-world applications.
2022
Abstract
A fundamental goal of scientific research is to learn about causal relationships. However, despite its critical role in the life and social sciences, causality has not had the same importance in Natural Language Processing (NLP), which has traditionally placed more emphasis on predictive tasks. This distinction is beginning to fade, with an emerging area of interdisciplinary research at the convergence of causal inference and language processing. Still, research on causality in NLP remains scattered across domains without unified definitions, benchmark datasets and clear articulations of the challenges and opportunities in the application of causal inference to the textual domain, with its unique properties. In this survey, we consolidate research across academic areas and situate it in the broader NLP landscape. We introduce the statistical challenge of estimating causal effects with text, encompassing settings where text is used as an outcome, treatment, or to address confounding. In addition, we explore potential uses of causal inference to improve the robustness, fairness, and interpretability of NLP models. We thus provide a unified overview of causal inference for the NLP community.

Abstract
From social media posts and text messages to digital government documents and archives, researchers are bombarded with a deluge of text reflecting the social world. This textual data gives unprecedented insights into fundamental questions in the social sciences, humanities, and industry. Meanwhile new machine learning tools are rapidly transforming the way science and business are conducted. Text as Data shows how to combine new sources of data, machine learning tools, and social science research design to develop and evaluate new insights.
Text as Data is organized around the core tasks in research projects using text—representation, discovery, measurement, prediction, and causal inference. The authors offer a sequential, iterative, and inductive approach to research design. Each research task is presented complete with real-world applications, example methods, and a distinct style of task-focused research.
Bridging many divides—computer science and social science, the qualitative and the quantitative, and industry and academia—Text as Data is an ideal resource for anyone wanting to analyze large collections of text in an era when data is abundant and computation is cheap, but the enduring challenges of social science remain.

Abstract
Topic models, as developed in computer science, are effective tools for exploring and summarizing large document collections. When applied in social science research, however, they are commonly used for measurement, a task that requires careful validation to ensure that the model outputs actually capture the desired concept of interest. In this paper, we review current practices for topic validation in the field and show that extensive model validation is increasingly rare, or at least not systematically reported in papers and appendices. To supplement current practices, we refine an existing crowd-sourcing method by Chang and coauthors for validating topic quality and go on to create new procedures for validating conceptual labels provided by the researcher. We illustrate our method with an analysis of Facebook posts by U.S. Senators and provide software and guidance for researchers wishing to validate their own topic models. While tailored, case-specific validation exercises will always be best, we aim to improve standard practices by providing a general-purpose tool to validate topics as measures.

Abstract
Text as data techniques offer a great promise: the ability to inductively discover measures that are useful for testing social science theories with large collections of text. Nearly all text-based causal inferences depend on a latent representation of the text, but we show that estimating this latent representation from the data creates underacknowledged risks: we may introduce an identification problem or overfit. To address these risks, we introduce a split-sample workflow for making rigorous causal inferences with discovered measures as treatments or outcomes. We then apply it to estimate causal effects from an experiment on immigration attitudes and a study on bureaucratic responsiveness.
2021

Abstract
How predictable are life trajectories? We investigated this question with a scientific mass collaboration using the common task method; 160 teams built predictive models for six life outcomes using data from the Fragile Families and Child Wellbeing Study, a high-quality birth cohort study. Despite using a rich dataset and applying machine-learning methods optimized for prediction, the best predictions were not very accurate and were only slightly better than those from a simple benchmark model. Within each outcome, prediction error was strongly associated with the family being predicted and weakly associated with the technique used to generate the prediction. Overall, these results suggest practical limits to the predictability of life outcomes in some settings and illustrate the value of mass collaborations in the social sciences.

Abstract
We make only one point in this article. Every quantitative study must be able to answer the question: what is your estimand? The estimand is the target quantity—the purpose of the statistical analysis. Much attention is already placed on how to do estimation; a similar degree of care should be given to defining the thing we are estimating. We advocate that authors state the central quantity of each analysis—the theoretical estimand—in precise terms that exist outside of any statistical model. In our framework, researchers do three things: (1) set a theoretical estimand, clearly connecting this quantity to theory; (2) link to an empirical estimand, which is informative about the theoretical estimand under some identification assumptions; and (3) learn from data. Adding precise estimands to research practice expands the space of theoretical questions, clarifies how evidence can speak to those questions, and unlocks new tools for estimation. By grounding all three steps in a precise statement of the target quantity, our framework connects statistical evidence to theory.
2020

Abstract
How predictable are life trajectories? We investigated this question with a scientific mass collaboration using the common task method; 160 teams built predictive models for six life outcomes using data from the Fragile Families and Child Wellbeing Study, a high-quality birth cohort study. Despite using a rich dataset and applying machine-learning methods optimized for prediction, the best predictions were not very accurate and were only slightly better than those from a simple benchmark model. Within each outcome, prediction error was strongly associated with the family being predicted and weakly associated with the technique used to generate the prediction. Overall, these results suggest practical limits to the predictability of life outcomes in some settings and illustrate the value of mass collaborations in the social sciences.

Abstract
Studies of economic mobility summarize the distribution of offspring incomes for each level of parent income. Mitnik and Grusky (2020) highlight that the conventional intergenerational elasticity (IGE) targets the geometric mean and propose a parametric strategy for estimating the arithmetic mean. We decompose the IGE and their proposal into two choices: (1) the summary statistic for the conditional distribution and (2) the functional form. These choices lead us to a different strategy—visualizing several quantiles of the offspring income distribution as smooth functions of parent income. Our proposal solves the problems Mitnik and Grusky highlight with geometric means, avoids the sensitivity of arithmetic means to top incomes, and provides more information than is possible with any single number. Our proposal has broader implications: the default summary (the mean) used in many regressions is sensitive to the tail of the distribution in ways that may be substantively undesirable.

Abstract
Social scientists are now in an era of data abundance, and machine learning tools are increasingly used to extract meaning from data sets both massive and small. We explain how the inclusion of machine learning in the social sciences requires us to rethink not only applications of machine learning methods but also best practices in the social sciences. In contrast to the traditional tasks for machine learning in computer science and statistics, when machine learning is applied to social scientific data, it is used to discover new concepts, measure the prevalence of those concepts, assess causal effects, and make predictions. The abundance of data and resources facilitates the move away from a deductive social science to a more sequential, interactive, and ultimately inductive approach to inference. We explain how an agnostic approach to machine learning methods focused on the social science tasks facilitates progress across a wide range of questions.

Abstract
Abstract: We identify situations in which conditioning on text can address confounding in observational studies. We argue that a matching approach is particularly well-suited to this task, but existing matching methods are ill-equipped to handle high-dimensional text data. Our proposed solution is to estimate a low-dimensional summary of the text and condition on this summary via matching. We propose a method of text matching, topical inverse regression matching, that allows the analyst to match both on the topical content of confounding documents and the probability that each of these documents is treated. We validate our approach and illustrate the importance of conditioning on text to address confounding with two applications: the effect of perceptions of author gender on citation counts in the international relations literature and the effects of censorship on Chinese social media users.
2019

Abstract

Abstract
2018
Abstract
Motivations like domain adaptation, transfer learning, and feature learning have fueled interest in inducing embeddings for rare or unseen words, n-grams, synsets, and other textual features. This paper introduces a la carte embedding, a simple and general alternative to the usual word2vec-based approaches for building such representations that is based upon recent theoretical results for GloVe-like embeddings. Our method relies mainly on a linear transformation that is efficiently learnable using pretrained word vectors and linear regression. This transform is applicable on the fly in the future when a new text feature or rare word is encountered, even if only a single usage example is available. We introduce a new dataset showing how the a la carte method requires fewer examples of words in context to learn high-quality embeddings and we obtain state-of-the-art results on a nonce task and some unsupervised document classification tasks.

Abstract
Massive open online courses (MOOCs) attract diverse student bodies, and course forums could potentially be an opportunity for students with different political beliefs to engage with one another. We test whether this engagement actually takes place in two politically-themed MOOCs, on education policy and American government. We collect measures of students’ political ideology, and then observe student behavior in the course discussion boards. Contrary to the common expectation that online spaces often become echo chambers or ideological silos, we find that students in these two political courses hold diverse political beliefs, participate equitably in forum discussions, directly engage (through replies and upvotes) with students holding opposing beliefs, and converge on a shared language rather than talking past one another. Research that focuses on the civic mission of MOOCs helps ensure that open online learning engages the same breadth of purposes that higher education aspires to serve.

Abstract
Recommendation systems are ubiquitous and impact many domains; they have the potential to influence product consumption, individuals' perceptions of the world, and life-altering decisions. These systems are often evaluated or trained with data from users already exposed to algorithmic recommendations; this creates a pernicious feedback loop. Using simulations, we demonstrate how using data confounded in this way homogenizes user behavior without increasing utility.

Abstract
In the past few decades new laws criminalizing certain transnational activities have proliferated: from money laundering, corruption, and insider trading to trafficking in weapons and drugs. Human trafficking is one example. We argue that criminalization of trafficking in persons has diffused in large part because of the way the issue has been framed: primarily as a problem of organized crime rather than predominantly an egregious human rights abuse. Framing human trafficking as an organized crime practice empowers states to confront cross-border human movements viewed as potentially threatening. We show that the diffusion of criminalization is explained by road networks that reflect potential vulnerabilities to the diversion of transnational crime. We interpret our results as evidence of the importance of context and issue framing, which in turn affects perceptions of vulnerability to neighbors' policy choices. In doing so, we unify diffusion studies of liberalization with the spread of prohibition regimes to explain the globalization of aspects of criminal law.
2017

Abstract
We present Discourse, a tool for coding and annotating MOOC discussion forum data. Despite the centrality of discussion forums to learning in online courses, few tools are available for analyzing these discussions in a context-aware way. Discourse scaffolds the process of coding forum data by enabling multiple coders to work with large amounts of forum data. Our demonstration will enable attendees to experience, explore, and critique key features of the app.
2016

Abstract
In this study, we develop methods for computationally measuring the degree to which students engage in MOOC forums with other students holding different political beliefs. We examine a case study of a single MOOC about education policy, Saving Schools, where we obtain measures of student education policy preferences that correlate with political ideology. Contrary to assertions that online spaces often become echo chambers or ideological silos, we find that students in this case hold diverse political beliefs, participate equitably in forum discussions, directly engage (through replies and upvotes) with students holding opposing beliefs, and converge on a shared language rather than talking past one another. Research that focuses on the civic mission of MOOCs helps ensure that open online learning engages the same breadth of purposes that higher education aspires to serve.

Abstract
Statistical models of text have become increasingly popular in statistics and computer science as a method of exploring large document collections. Social scientists often want to move beyond exploration, to measurement and experimentation, and make inference about social and political processes that drive discourse and content. In this paper, we develop a model of text data that supports this type of substantive research.
Our approach is to posit a hierarchical mixed membership model for analyzing topical content of documents, in which mixing weights are parameterized by observed covariates. In this model, topical prevalence and topical content are specified as a simple generalized linear model on an arbitrary number of document-level covariates, such as news source and time of release, enabling researchers to introduce elements of the experimental design that informed document collection into the model, within a generally applicable framework. We demonstrate the proposed methodology by analyzing a collection of news reports about China, where we allow the prevalence of topics to evolve over time and vary across newswire services. Our methods quantify the effect of news wire source on both the frequency and nature of topic coverage.

2015

Abstract
Content analysis, a widely-applied social science research method, is increasingly being supplemented by topic modeling. However, while the discourse on content analysis centers heavily on reproducibility, computer scientists often focus more on scalability and less on coding reliability, leading to growing skepticism on the usefulness of topic models for automated content analysis. In response, we introduce TopicCheck, an interactive tool for assessing topic model stability. Our contributions are threefold. First, from established guidelines on reproducible content analysis, we distill a set of design requirements on how to computationally assess the stability of an automated coding process. Second, we devise an interactive alignment algorithm for matching latent topics from multiple models, and enable sensitivity evaluation across a large number of models. Finally, we demonstrate that our tool enables social scientists to gain novel insights into three active research questions.

Abstract
In political science, research using computer-assisted text analysis techniques has exploded in the last fifteen years. This scholarship spans work studying political ideology,1 congressional speech,2 representational style,3 American foreign policy,4 climate change attitudes,5 media,6 Islamic clerics,7 and treaty making,8 to name but a few. As these examples illustrate, computer-assisted text analysis—a prime example of mixed-methods research—allows gaining new insights from long-familiar political texts, like parliamentary debates, and altogether enables the analysis to new forms of political communication, such as those happening on social media. While the new methods greatly facilitate the analysis of many aspects of texts and hence allow for content analysis on an unprecedented scale, they also challenge traditional approaches to research transparency and replication.9 Specific challenges range from new forms of data pre-processing and cleaning, to terms of service for websites, which may explicitly prohibit the redistribution of their content. The Statement on Data Access and Research Transparency10 provides only very general guidance regarding the kind of transparency positivist empirical researchers should provide. In this paper, we consider the application of these general guidelines to the specific context of computer-assisted text analysis to suggest what transparency demands of scholars using such methods. We explore the implications of computer-assisted text analysis for data transparency by tracking the three main stages of a research project involving text as data: (1) acquisition, where the researcher decides what her corpus of texts will consist of; (2) analysis, to obtain inferences about the research question of interest using the texts; and (3) ex post access, where the researcher provides the data and/or other information to allow the verification of her results. To be transparent, we must document and account for decisions made at each stage in the research project. Transparency not only plays an essential role in replication11 but it also helps to communicate the essential procedures of new methods to the broader research community. Thus transparency also plays a didactic role and makes results more interpretable. Many transparency issues are not unique to text analysis. There are aspects of acquisition (e.g., random selection), analysis (e.g., outlining model assumptions), and access (e.g., providing replication code) that are important regardless of what is being studied and the method used to study it. These general issues, as well as a discussion of issues specific to traditional qualitative textual analysis, are outside of our purview. Instead, we focus here on those issues that are uniquely important for transparency in the context of computer-assisted text analysis.

Abstract
Dealing with the vast quantities of text that students generate in a Massive Open Online Course (MOOC) is a daunting challenge. Computational tools are needed to help instructional teams uncover themes and patterns as MOOC students write in forums, assignments, and surveys. This paper introduces to the learning analytics community the Structural Topic Model, an approach to language processing that can (1) find syntactic patterns with semantic meaning in unstructured text, (2) identify variation in those patterns across covariates, and (3) uncover archetypal texts that exemplify the documents within a topical pattern. We show examples of computationally- aided discovery and reading in three MOOC settings: mapping students’ self-reported motivations, identifying themes in discussion forums, and uncovering patterns of feedback in course evaluations.

Abstract
Recent advances in research tools for the systematic analysis oftextual data are enabling exciting new research throughout the socialsciences. For comparative politics scholars who are often interestedin non-English and possibly multilingual textual datasets, theseadvances may be difficult to access. This paper discusses practicalissues that arise in the the processing, management, translation andanalysis of textual data with a particular focus on how proceduresdiffer across languages. These procedures are combined in two appliedexamples of automated text analysis using the recently introducedStructural Topic Model. We also show how the model can be used toanalyze data that has been translated into a single language viamachine translation tools. All the methods we describe here are implemented in open-source software packages available from the authors.
2014

Abstract
Content analysis, a labor-intensive but widely-applied research method, is increasingly being supplemented by computational techniques such as statistical topic modeling. However, while the discourse on content analysis centers heavily on reproducibility, computer scientists often focus more on increasing the scale of analysis and less on establishing the reliability of analysis results. The gap between user needs and available tools leads to justified skepticism, and limits the adoption and effective use of computational approaches. We argue that enabling human-in-the-loop machine learning requires establishing users’ trust in computer-assisted analysis. To this aim, we introduce our ongoing work on analysis tools for interac- tively exploring the space of available topic models. To aid tool development, we propose two studies to examine how a computer-aided workflow affects the uncovered codes, and how machine-generated codes impact analysis outcome. We present our prototypes and findings currently under submission.
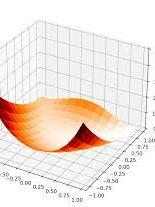
Abstract
This vignette introduces the lbfgs package for R, which consists of a wrapper built around the libLBFGS optimization library written by Naoaki Okazaki. The lbfgs package implements both the Limited-memory Broyden-Fletcher-Goldfarb-Shanno (L-BFGS) and the Orthant-Wise Limited-memory Quasi-Newton (OWL-QN) optimization algorithms. The L-BFGS algorithm solves the problem of minimizing an objective, given its gradient, by iteratively computing approximations of the inverse Hessian matrix. The OWL-QN algorithm finds the optimum of an objective plus the L1 norm of the problem’s parameters. The package offers a fast and memory-efficient implementation of these optimization routines, which is particularly suited for high-dimensional problems. The lbfgs package compares favorably with other optimization packages for R in microbenchmark tests.
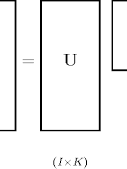
Abstract
In this paper I present a general framework for regression in the presence of complex dependence structures between units such as in time-series cross-sectional data, relational/network data, and spatial data. These types of data are challenging for standard multilevel models because they involve multiple types of structure (e.g. temporal effects and cross-sectional effects) which are interactive. I show that interactive latent factor models provide a powerful modeling alternative that can address a wide range of data types. Although related models have previously been proposed in several different fields, inference is typically cumbersome and slow. I introduce a class of fast variational inference algorithms that allow for models to be fit quickly and accurately.

Abstract
Collection and especially analysis of open-ended survey responses are relatively rare in the discipline and when conducted are almost exclusively done through human coding. We present an alternative, semi-automated approach, the structural topic model (STM) (Roberts, Stewart, and Airoldi 2013; Roberts et al. 2013), that draws on recent developments in machine learning based analysis of textual data. A crucial contribution of the method is that it incorporates information about the document, such as the author’s gender, political affiliation, and treatment assignment (if an experimental study). This article focuses on how the STM is helpful for survey researchers and experimentalists. The STM makes analyzing open-ended responses easier, more revealing, and capable of being used to estimate treatment effects. We illustrate these innovations with analysis of text from surveys and experiments.
2013
Abstract
We develop the Structural Topic Model which provides a general way to incorporate corpus structure or document metadata into the standard topic model. Document-level covariates enter the model through a simple generalized linear model framework in the prior distributions controlling either topical prevalence or topical content. We demonstrate the model’s use in two applied problems: the analysis of open-ended responses in a survey experiment about immigration policy, and understanding differing media coverage of China’s rise.

Abstract
We describe a new probabilistic model for extracting events between major political actors from news corpora. Our unsupervised model brings together familiar components in natural language processing (like parsers and topic models) with contextual political information— temporal and dyad dependence—to infer latent event classes. We quantitatively evaluate the model’s performance on political science benchmarks: recovering expert-assigned event class valences, and detecting real-world conflict. We also conduct a small case study based on our model’s inferences. A supplementary appendix, and replication software/data are available online, at: http://brenocon.com/irevents

Abstract
This supplemental appendix provides additional methodological details, additional results and visualizations of models in the main paper. Results are organized according to the dependent variable under study.

Abstract
Politics and political conflict often occur in the written and spoken word. Scholars have long recognized this, but the massive costs of analyzing even moderately sized collections of texts have prevented political scientists from using texts in their research. Here lies the promise of automated text analysis: it substantially reduces the costs of analyzing large collections of text. We provide a guide to this exciting new area of research and show how, in many instances, the methods have already obtained part of their promise. But there are pitfalls to using automated methods. Automated text methods are useful, but incorrect, models of language: they are no substitute for careful thought and close reading. Rather, automated text methods augment and amplify human reading abilities. Using the methods requires extensive validation in any one application. With these guiding principles to using automated methods, we clarify misconceptions and errors in the literature and identify open questions in the application of automated text analysis in political science. For scholars to avoid the pitfalls of automated methods, methodologists need to develop new methods specifically for how social scientists use quantitative text methods.

Abstract
In examining the diffusion of social and political phenomena like regime transition, conflict, and policy change, scholars routinely make choices about how proximity is defined and which neighbors should be considered more important than others. Since each specification offers an alternative view of the networks through which diffusion can take place, one’s decision can exert a significant influence on the magnitude and scope of estimated diffusion effects. This problem is widely recognized, but is rarely the subject of direct analysis. In international relations research, connectivity choices are usually ad hoc, driven more by data availability than by theoretically informed decision criteria. We take a closer look at the assumptions behind these choices, and propose a more systematic method to asses the structural similarity of two or more alternative networks, and select one that most plausibly relates theory to empirics. We apply this method to the spread of democratic regime change, and offer an illustrative example of how neighbor choices might impact predictions and inferences in the case of the 2011 Arab Spring.
2012
